NAME __________________________________
Biology Department
Statistics Lab, M. J. Malachowski, Ph.D
Many of you know what an average is. But, be aware, there are two close relative to average, the median and the mode. Together, these are called measures of central tendency. Each of these gives us a slightly different "view" or "take" on a range (highest and lowest values in the set of numbers with which we are working) of figures.
The Average (also called arithmetic mean) is the most common of these measurs. We use it to estimate the strength of a range of values – for example, sports scores, stock prices, or temperature. To find an average, you add the values entered in the range, they divide the total by the number of entries.
The Median tells you what value lies exactly in the middle between the highest and lowest values within the range. In other words, half of the numbers have values that are greater than the median, and half of the numbers have values that are less than the median. This might be important, if you, for example, have a lot of low values and one or two very high ones. Averaging these values could give you an inflated idea of the whole, but the median is a true picture of the middle of the group.
Let's say that our Chancellor joined our instructor's bar-B-Q. If you recalculated the median average salary of the group, it might not even change, but the groups average salary would increase significantly.
The Mode is somewhat different. It reports which value occurs most often in a range. This would be useful in estimating, e.g., what score you are most likely to obtain on a test, or what denomination bill to request as change at the bank. If no value is ever repeated in the range, there is no mode.
If you have a dozen values and only one of them repeats, say 4 times, then that number is the mode. It does not matter if the repeats were at the high end, the low end, or in the middle. Mode only cares about frequency. There may be more than one mode, a bimodal curve.
The Range of the provides the entire extent of values from the lowest to the highest in the group.
The Standard Deviation (SD) provides a predictive description of the spread of data. It is based on the average spread in our sample. Having determined the mean, we can determine the deviation of the individual items from the mean for each item. Since we have a large sample, we can use a working equation to calculate the SD for our data.
The advantage of using the standard deviation as a descriptive tool is that in a normally distributed population, exactly 68.27 % of the measurements will fall within 1 standard deviation from the mean. (that is, +/- 1 SD from the mean), exactly 95.45 % of the measurements will fall within 2 standard deviations from the mean, and exactly 99.73 % of the measurements will fall within 3 standard deviations from the mean.
SD = ( ( Sx2 - [(Sx)2 / n] / (n-1))1/2
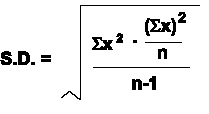
Where: