Memory Management
This chapter discusses memory management in Linux.
Virtual Memory
A landlord has a single room apartment that is available for rent for 1 person. Two people come to the apt and want to stay but are told the apartment is only for 1 person. The people say that one has a daytime job from 8am to 8pm and the other person works from 8pm to 8am. So only 1 person uses the room at a time but 2 people are staying in the room. An outsider sees 2 people using the room. That is essentially how virtual memory works.
The way a program is run in general on a computer is as follows: it is loaded into the RAM by the operating system. The CPU fetches an instruction from the RAM and executes it. The RAM is more expensive and faster compared to the hard drive. An operating system can move a program in the RAM that is not being used to the hard drive and then later on move it back to RAM when it is needed. It gives the illusion of having more memory than there really is. This way we can load more programs and run them compared to the non-virtual scheme. When things are written out to the swap space they are written out in chunks ( usually a few kilobytes ). These chunks are called pages.
On our windows computers we can see this by
using the "sysinfo" command.
See full image
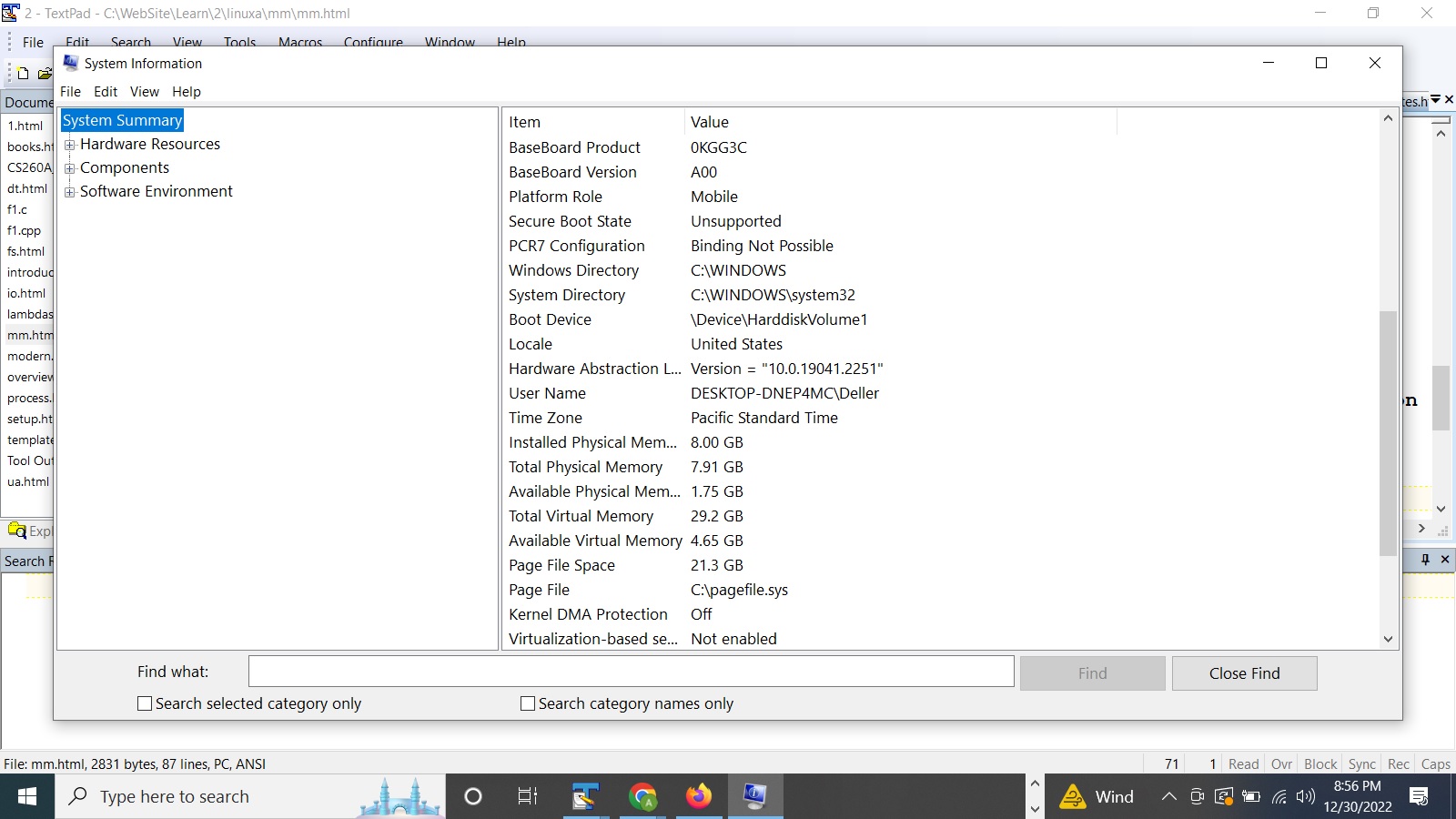
We see in the above image that the actual physical memory is 8 Gb and the space reserved
on disk ( called the swap space ) is around 21 Gb giving us the total virtual memory of
around 29 Gb. Well if hard drive is cheap why don't we just increase the swap space to 100 Gb
and get lot more virtual memory ? The problem is that then the system will have to do
a lot of swapping( moving things between the RAM and the hard drive) and that itself
will slow things down as reading from the RAM is much faster than reading from the hard
drive. So we will usually see that the swap space is not all that large compared to the
RAM size. In the image above we see that the swap space is stored in a file
called "C:\pagefile.sys" .
We can use the "cat /proc/meminfo" command to view memory information on a Linux system.
[amittal@hills process]$ cat /proc/meminfo MemTotal: 12056544 kB MemFree: 4466564 kB MemAvailable: 6664760 kB Buffers: 0 kB Cached: 2355584 kB SwapCached: 36 kB Active: 1497052 kB Inactive: 3610212 kB Active(anon): 368460 kB Inactive(anon): 3000008 kB Active(file): 1128592 kB Inactive(file): 610204 kB Unevictable: 0 kB Mlocked: 0 kB SwapTotal: 8388604 kB SwapFree: 8387240 kB Dirty: 0 kB Writeback: 0 kB AnonPages: 2751720 kB Mapped: 216840 kB Shmem: 616788 kB KReclaimable: 780724 kB Slab: 1284884 kB SReclaimable: 780724 kB SUnreclaim: 504160 kB KernelStack: 12688 kB PageTables: 25560 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 14416876 kB Committed_AS: 3787844 kB VmallocTotal: 34359738367 kB VmallocUsed: 0 kB VmallocChunk: 0 kB Percpu: 588800 kB HardwareCorrupted: 0 kB AnonHugePages: 2510848 kB ShmemHugePages: 0 kB ShmemPmdMapped: 0 kB FileHugePages: 0 kB FilePmdMapped: 0 kB HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 0 kB DirectMap4k: 1642304 kB DirectMap2M: 10940416 kB DirectMap1G: 2097152 kB [amittal@hills process]$
From the above the physical RAM is about 12 Gb ( MemTotal field ) and the the swap size is around 8 Gb ( SwapTotal ). The output of "meminfo" shows statistics and is not something that we can tune or adjust. Let's study the output of "meminfo" in little bit more detail.
MemTotal: 12056544 kB MemFree: 4466564 kB MemAvailable: 6664760 kBWe know that "MemTotal" is the total physcial memory. The "MemFree" is memory that is currently unused by the system. The "MemAvailable" is being used but can be freed up. This number is an estimate.
Buffers: 0 kB Cached: 2355584 kBBuffers is used by processes for input/output. Suppose we are sending information to the printer that is slow but our program is sending that information very fast then we can create a buffer and send the data to the printer from the buffer.Buffers are short lived.
Cached is used for disk cache. This can be used to speed up access to the hard drive.Suppose we read from a file. It's possible that another program requests the same data soon after. We can serve the data from the cache instead of going to the hard drive. Another scenario is that there are multiple writes to the disk. We can store those writes in the cache and then write all the small writes in one big write to the disk. Total page cached size is the sum of "Cached" and "SwapCached" .
There are quite a few entries in the output. Many of the entries are complex to understand without going through a lot of details regarding architecture and memory. The below contains brief descriptions.
Amount of swap used for cached memory. This is a list of page table entries. Each entry contains information about the page such as the file the page has been swapped to. SwapCached: 36 kB Active: 1497052 kB Inactive: 3610212 kB Active(anon): 368460 kB Inactive(anon): 3000008 kB Active(file): 1128592 kB Inactive(file): 610204 kB Unevictable: 0 kB Mlocked: 0 kB Roughly 8 gb of swap memory out of which almost all of it is free. SwapTotal: 8388604 kB SwapFree: 8387240 kB Amount of memory waiting to be written back to the disk. Dirty: 0 kB Total amount of memory that is actively being written to the disk. Writeback: 0 kB AnonPages: 2751720 kB Total amount of memory that have been used to map devices, files or libraries Mapped: 216840 kB Shmem: 616788 kB KReclaimable: 780724 kB Memory used by the kernel for it's own data structures. Slab: 1284884 kB SReclaimable: 780724 kB SUnreclaim: 504160 kB KernelStack: 12688 kB PageTables: 25560 kB NFS_Unstable: 0 kB Bounce: 0 kB WritebackTmp: 0 kB CommitLimit: 14416876 kB Committed_AS: 3787844 kB Total amount of space for virtual address space. This is based on the number of bits we have for an address and page size. This is not the actualy virtual memory. In fact the below number is in TeraBytes. This is the theoretical total address space we can possibly use. VmallocTotal: 34359738367 kB VmallocUsed: 0 kB VmallocChunk: 0 kB Percpu: 588800 kB HardwareCorrupted: 0 kB AnonHugePages: 2510848 kB ShmemHugePages: 0 kB ShmemPmdMapped: 0 kB FileHugePages: 0 kB FilePmdMapped: 0 kB We have the feature of huge pages for virtual memory. This will make the swapping process to the hard drive a bit more efficient. HugePages_Total: 0 HugePages_Free: 0 HugePages_Rsvd: 0 HugePages_Surp: 0 Hugepagesize: 2048 kB Hugetlb: 0 kB A translation lookaside buffer (TLB) is a memory cache that stores the transactions of pages from virtual memory to physical ram. The below entries roughly show how many pages were being transferred. The amounts correspond to the total memory of the pages that have been transferred. DirectMap4k: 1642304 kB DirectMap2M: 10940416 kB DirectMap1G: 2097152 kBAnother command to print memory information ( output is much simpler ) is the free command. Running this on the hills server produces the following output.
[amittal@hills dev]$ free -h
total used free shared buff/cache available
Mem: 11Gi 2.2Gi 2.0Gi 594Mi 7.4Gi 8.5Gi
Swap: 8.0Gi 1.0Mi 8.0Gi
[amittal@hills dev]$
The total shows the physical and the swap memory sizes. The meminfo run at the same
time shows:Cached: 6890100 kB
We have discussed cache above. Linux can free this up and make this available if it wants to. Another command is the "swapon" command.
[amittal@hills dev]$ swapon -s Filename Type Size Used Priority /dev/dm-1 partition 8388604 1584 -2 [amittal@hills devWe can use a disk file for the swap space or a hard drive partition. It is easier to change the disk file rather than change a partition. However if we know the size before hand then we can use a partition. Linux also allows multiple swap spaces consisting of files or partitions. If we need a large amount of swap space we can add it without bringing down the system and then get rid of it once we are done with our special need. In the above the device being used for swap space is "/dev/dm-1" and it is a partition of which 8Gb is reserved for the partition.
Creating swap space
We can use a file for a swap space. It must not have any "holes". It's possible that some data is written at an offset to the size of the file and this produces a hole in the file which is filled up all zeroes. Many modern filesystem will not actually write these zeroes on the disk but rather keep this information in the inode structure. The result is that the actual size of file on the hard disk is much smaller. The concept of a hole in a file may be better understood with an example. The "dd" command ( disk/data duplicator) is used to copy raw data from one source to another.[amittal@hills temp]$ dd if=/dev/urandom bs=4096 count=2 of=file_with_holes 2+0 records in 2+0 records out 8192 bytes (8.2 kB, 8.0 KiB) copied, 0.000273703 s, 29.9 MB/s [amittal@hills temp]$ ls -l file_with_holes -rw------- 1 amittal csdept 8192 Mar 11 18:13 file_with_holes [amittal@hills temp]$ dd if=/dev/urandom bs=4096 seek=7 count=2 of=file_with_holes 2+0 records in 2+0 records out 8192 bytes (8.2 kB, 8.0 KiB) copied, 0.000235385 s, 34.8 MB/s [amittal@hills temp]$ ls -l file_with_holes -rw------- 1 amittal csdept 36864 Mar 11 18:13 file_with_holes [amittal@hills temp]$We first create a file with 2 blocks of size 4096 in the first "dd" command. The "if" option reads from the random file so we get random data and the output file is "file_with_holes". We run another "dd" command but we start writing at 7th block of 4096 and we write 2 blocks. So we have written ( 4096*4) byest and skipped ( 7-3 = 4 blocks ), the same amount. So our file size is roughly 36Kb. We can transfer this file to our windows system and open it with Textpad in binary format.
See full image
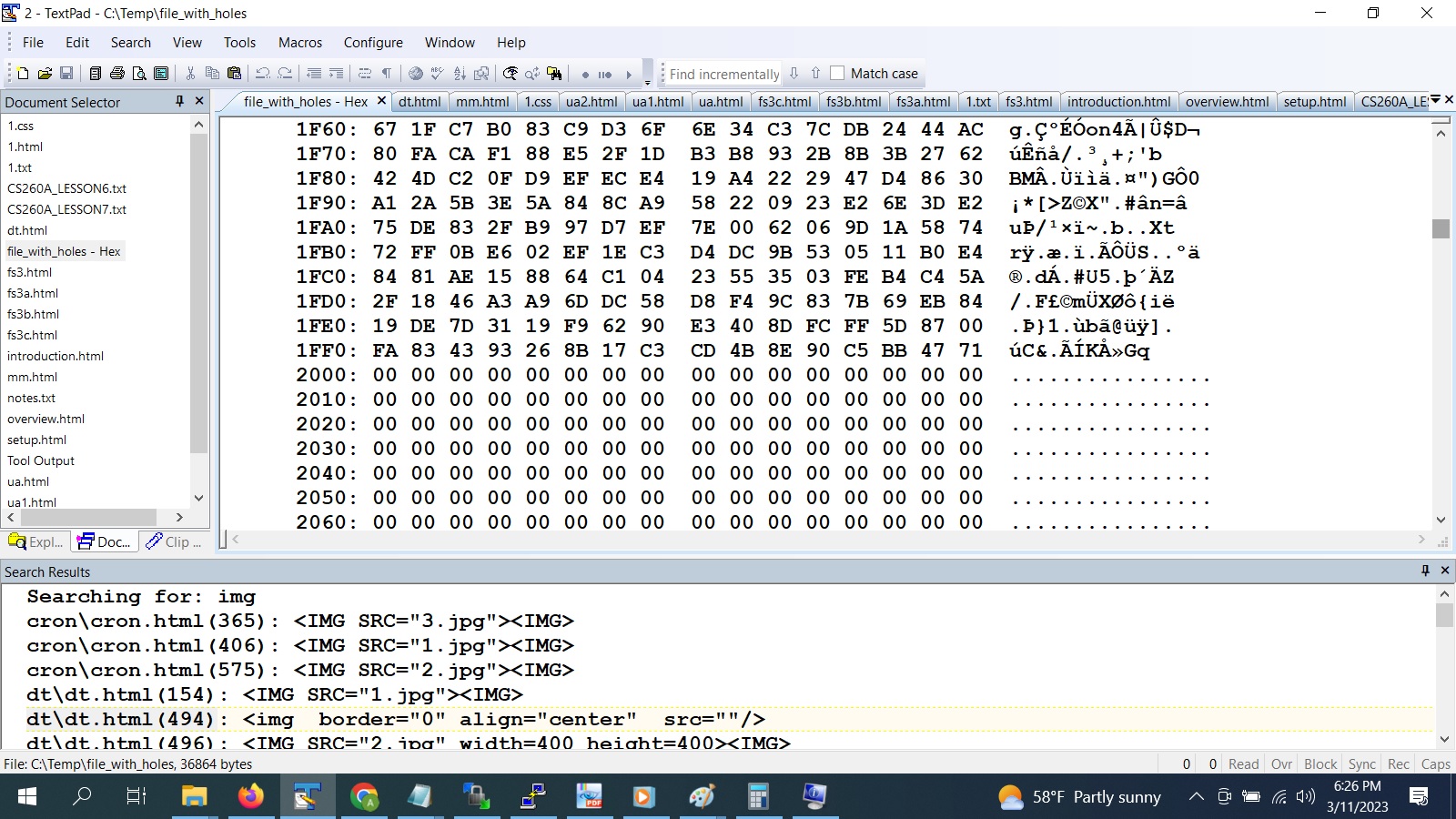
We can see how the zeroes start after 8192 byes( The 2000 on the leftmost is in hexadecimal...16 to the power 3 times 2 is 8192). Even though we see the zeroes in the image above it's quite possible the zeroes are not on the hard drive file data. Files with holes are also called sparse files and are useful when we need a large offset address in the file without the file having the actual space allocated on the hard drive. We can also use the "truncate" command to create the file and then use "du" command to see the actual size on disk. Example:
[amittal@hills temp]$ du -h file_with_holes 16K file_with_holes [amittal@hills temp]$ du -h --apparent-size file_with_holes 36K file_with_holes [amittal@hills temp]$ truncate -s 1M another_file [amittal@hills temp]$ ls -l another_file -rw------- 1 amittal csdept 1048576 Mar 11 18:53 another_file [amittal@hills temp]$
Having a hole in the file makes things complicated for the kernel that just wants to write pages to the disk sectors and if a disk sector has not been allocated due to holes then it's a problem. There is the "/dev/zero" file that we can use to create our swap file. The "/dev/zero" is a file that when we read from it gives us null values. It is useful for initializing the data. The memory page is of size 4kb so if our block size is 1Kb we should make the count value to be a multiple of 4.
ajay@ajkumar08-PC:~$ cd /home/ajay/temp/swap ajay@ajkumar08-PC:~/temp/swap$ dd if=/dev/zero of=extra-swap bs=1024 count=1024 1024+0 records in 1024+0 records out 1048576 bytes (1.0 MB, 1.0 MiB) copied, 0.016882 s, 62.1 MB/s ajay@ajkumar08-PC:~/temp/swap$ ajay@ajkumar08-PC:~/temp/swap$ swapon -s Filename Type Size Used P riority /dev/sda5 partition 999420 0 - 2 ajay@ajkumar08-PC:~/temp/swap$ swapon --show NAME TYPE SIZE USED PRIO /dev/sda5 partition 976M 0B -2 We associate the swap file but it's not enabled yet. ajay@ajkumar08-PC:~/temp/swap$ mkswap extra-swap mkswap: extra-swap: insecure permissions 0644, 0600 suggested. Setting up swapspace version 1, size = 1020 KiB (1044480 bytes) no label, UUID=e14948d2-45d7-47f7-9638-a58f5521795c ajay@ajkumar08-PC:~/temp/swap$ Login as root. ajay@ajkumar08-PC:~/temp/swap$ su root Password: Now enable it . root@ajkumar08-PC:/home/ajay/temp/swap# swapon extra-swap swapon: /home/ajay/temp/swap/extra-swap: insecure file owner 1000, 0 (root) suggested. Check that the entry got added. root@ajkumar08-PC:/home/ajay/temp/swap# swapon -s Filename Type Size Used Priority /dev/sda5 partition 999420 0 -2 /home/ajay/temp/swap/extra-swap file 1020 0 -3 Higher number means higher priority. Removing the entry root@ajkumar08-PC:/home/ajay/temp/swap# swapoff -v /home/ajay/temp/swap/extra-swap swapoff /home/ajay/temp/swap/extra-swap root@ajkumar08-PC:/home/ajay/temp/swap# swapon -s Filename Type Size Used Priority /dev/sda5 partition 999420 0 -2 root@ajkumar08-PC:/home/ajay/temp/swap# root@ajkumar08-PC:/home/ajay/temp/swap# We can delete the file also at this stage.If we want to retain the swap entry we can modify the "/etc/fstab" file so that when the system restarts it will use our swap file. Instead of a file we could have used a partition also.
Allocating Swap Space
How much space should be allocated for the swap space. The windows shapshot show the RAM as 16Gb and swap space as 5.25 Gb. On the hills server we have the RAM as 12Gb and swap space as 8Gb. On anothe Linux system the RAM is 2Gb and the swap space is 1Gb. There is no formula to figure out the swap space. We need to figure out what applications will run at the same time and what the maximum memory usage might be. Also take into account how many people will be using the system at the same time. As discussed previously the swap space cannot be very large because swapping itself( moving pages from the RAM to the hard drive and vice versa ) is a slow task. Even if the RAM is large enough we should still have some swap space. Linux takes an aggresive approach to swapping. If a program is not being used then it might be swapped even if there is available RAM. That way Linux does not have to spend time swapping if RAM is needed. Swap space can be spread over multiple disk, partitions and files.Buffer Cache
We have discussed this topic briefly above.If a file is read it's possible that there might be a request for the same data. It's very expensive to read from the disk every time. Rather we can store this data in the RAM. Another case might be to run the command "ls" and save the results in RAM. If another request comes soon after then we can server the results from the RAM cache instead of another execution of the command. We need to take care of when the data becomes stale if the data changes.The RAM used for this activity is called buffer cache. We can see it's size in the output of the "free -h" command under the "cache" field.We can use a portion of the RAM for this cache and if it gets filled up then the unused parts are discarded to make room for new data. Disk writes can also be cached and written to the disk later on.
Buffer caches can work in different ways. The write-through method will write to the cache and write to the disk at the same time.The write-back method will write to the cache but write to the disk later on.The write-back is more efficient but introduces another problem. What if some writes are written to the cache and the power goes off. The changes in the cache are lost and it's possible the files system is not in a clean state. The "sync" command will cause all the writes in the cache to be written out to the disk.
The size of the cache will vary. If the cache is very big then the normal programs will not fit in RAM and there will be swapping which is itself slow. Linux will try to use as much of the free RAM for cache and if programs need more memory then it will reduce the size of the cache.