| sections in this module | City College of San Francisco - CS260A Unix/Linux System Administration Module: Filesystems I |
module list |
Before we learn how to create a filesystem, we must discuss a few parameters important for its creation. These are
It is also helpful to create the filesystem label when the filesystem is created, so we will discuss why labeling is a good idea here as well.
Note: this discussion illustrates the standard linux filesystem, ext2/ext3.
Block Size (first, let's discuss the legacy issues for ext2/3 filesystems)
From the previous discussion about the Berkeley Fast File System you should be aware that the filesystem block size is an important filesystem parameter. As we saw, it affects the percentage of wasted space on the system and the amount of fragmentation. On linux filesystems, however, we have little choice in the blocksize. This choice is currently limited to 1k, 2k or 4k blocks. Even this choice, however, can have significant effects.
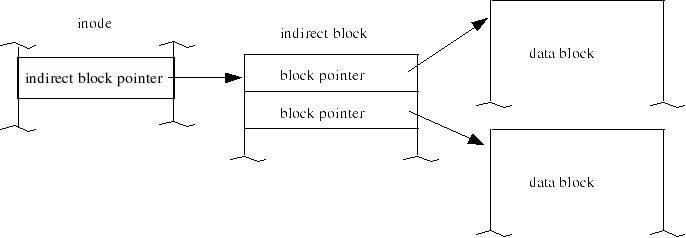
To appreciate fully the effect of filesystem block size, we must learn something more how a file's data is accessed on ext2/ext3 filesystems. (The concepts here apply to all Unix filesystems, but the specifics may vary.) Half of the space in each inode is reserved for block addresses. Each block address describes the location of one filesystem block assigned to the file. The current implementation of ext2 has room in the inode for 15 block addresses. If each block address directly referenced a disk block and the blocksize was 1kB, the file could grow to the mind-boggling size of 15kB.
Only the first 12 of the block addresses are direct references (pointers) to actual data blocks. These 12 blocks are called direct blocks. The remaining three use indirection to greatly increase the maximum size of a file on linux. The first of these remaining three block addresses is a pointer to an indirect block. This means the block address in the inode locates a block of block addresses:
The second of the remaining block addresses in the inode is a pointer to a doubly-indirect block. This is a block of addresses of indirect blocks, each of which locates a block of block addresses. The last of the remaining blocks is a triply-indirect block. Hopefully you can extrapolate to how the triply-indirect block works.
Let's do the arithmetic here for two different blocksizes: 1kB and 4kB. Here, block addresses are 32-bits, or 4 bytes each.
| Block Size | Amount of data addressed by 12 direct blocks | Number of block addresses that can be stored in a single block | Amount of data addressed by one indirect block | Amount of data addressed by one doubly indirect block |
Amount of data addressed by one triply-indirect block | Maximum file size |
| 1k | 12*1k = 12kB |
1024/4 = 256 |
256*1k= 256kB |
256*256*1k= 65.5MB |
256*256*256*1k= 16.7GB |
16.7GB |
| 4k | 12*4k = 48kB |
4096/4 = 1024 |
1024*4k= 4MB |
1024*1024*4k= 4GB |
1024*1024*1024*4k= 4TB |
4 TB |
As you can see, increasing the filesystem block size greatly increased the maximum size of the file. It also makes the access of any file up to 4MB considerably faster. I'm not sure if file sizes of the maximum (four terabytes) are actually implemented on most linux systems, but this is the limit of the addressing capability with this configuration of block addresses in the inode. (It also approaches the limit of addressing using 32-bit block addresses. The maximum unsigned 32-bit number is 4GB (actually, 4GB-1, but 0 could be the first block address). This will address 4TB of data using 1kB blocks, or 16TB of data using 4kB blocks.)
Filesystem block size has an effect on filesystem performance as well. The more levels of indirection that are necessary to get to the data, the slower the access becomes. The 4k filesystem will access up to a 48kB file without resorting to indirect blocks. It will also reference a file of up to 4MB without resorting to doubly-indirect addressing.
When a filesystem is created, the block size is set. If you do not choose the block size, a formula is used to calculate the appropriate block size based on the size of the partiton. If, however, you know in advance that your filesystem will contain a large number of large, or small, files, you may want to choose your own blocksize.
You can discover the blocksize of any filesystem by a simple test.
Go to a directory on that filesystem that allows you to write to it and
create a small file using echo. Then use the du -sk command on the file and see how many kB of space was allocated.
Block Size on filesystems that use extents
On ext4 and xfs filesystems, the blocksize is not as important, since extents combine blocks to form larget contiguous areas. However, smaller blocks eventually cause more fragmentation, so, if you have a filesystem and dont care how much space your small files take, a larger blocksize is better. Currently, however, it is not possible to increase the block size of linux filesystems beyond the system page size (4kiB), making it silly to create a filesystem with a blocksize that is smaller.
On filesystems that use extents, the array of block pointers in the
inode is overlaid with a sequence of extent structures. Each extent
structure can refer to a contiguous area of some number of blocks. This
is currently 2^15 blocks on ext4 (at a 4kiB blocksize this is a maximum
extent size of 128MiB). I assume this maximum is much larger on xfs,
since it is a 64-bit filesystem, but I couldn't find the parameter.
Free extents are stored by extent size on both filesystems, but the
structure for finding them is more efficient in xfs.
Maximum File and Filesystem Size
Currently, the maximum size of an ext4 file and of an ext4 filesystem (according to Redhat documentation) is 8TiB (which is limited by a 32-bit number holding the block number). The theoretical maximum size of an ext4 filesystem is 2^16 extents. But, since it is a 32-bit filesystem and the block number must fit in 32 bits, very few extents are used.
As prevously mentioned, xfs is a true 64-bit filesystem. The maximum
size of a file and of the filesystem is in the EiB range (exbibyte -
10^60 bytes, or a GiB of TiB), which is at least two full-length
3D-ultra-HD movies. [ just kidding - for a metric, here are a couple of
comparisons: The entire world's ability to exchange information via
two-way communication networks (internet, telephone, etc) in 2007 was
less than 60 EiB per day. The largest storage array ever built as of
2012 has a capacity of 1/2 EiB. ]
Inodes
All the inodes the filesystem will ever have are created when the filesystem is created. Thus, if you run out of inodes, you cannot create any new files. In this case, it doesn't matter how much free data space you have, the space is unusable! For this reason, the system is very conservative about creating sufficient inodes. The default algorithm is to create an inode for every few kB of data.
Inodes are not free, however. An inode on a 32-bit filesystem takes up 128 bytes of space. If a filesystem allocates one inode per two data blocks and data blocks are 1kB each, 1/16 of the space on the filesystem is occupied by inodes. This 6.66% loss may not be important, but if you are using the partition for video files, it is silly. In this case, the partition could be 100GB, and each file could consume several GB. You would be giving up 7GB to store 50 million unused inodes.
The ratio of data bytes to inodes can be specified when the filesystem is created to override use of the default algorithm.
You can see the status of inodes on your mounted filesystems using the -i option to df.
Filesystem labels
As many of us know, drives on a PC normally use drive letters. These drive letters are assigned by the BIOS at boot time and are use to identify drives to the system. The drive letter the BIOS assigns to a particular drive can change between system boots if the system's drives are reconfigured: either by physically rearranging IDE drives or changing the SCSI id of SCSI drives. Then, when linux boots, the drive which was formerly identified as A: is now identified as B:. Since device files use this BIOS-assigned drive letter to associate device files with drives, the partition that was hda1 is now hdb1. If linux is configured to mount drives by their device files, disaster occurs. If this error occurs on the /boot or / drive, the system will not even boot.
An alternate method for identifying partitions to the boot loader (and to the kernel when it starts) is to label each partition with a short unique label. This label identifies the partition. When a partition is mounted using its label, the system scans the drives on the system for a partition with that label, rather than relying on the drive letters the BIOS assigned.
The label is part of the filesystem, so it cannot be set prior to filesystem creation. It can be set at the same time by an option to mke2fs. It can also be set later by either e2label or the filesystem tuning program tune2fs. You can use e2label to query the label as well.
We will discuss more on labels when we create a filesystem.
On current linux systems a universally unique identifer (UUID) is
generated, placed in the superblock, and used to identify the filesystem rather than a label.
Although more cumbersome to deal with manually, UUIDs are guaranteed to
be unique.
On our systems, a UUID is automatically generated by mkfs when the filesystem is created. You can generate your own UUID using uuidgen(1) and add it to the filesystem using tune2fs.
Reserved block percentage
When a filesystem is created, a small percentage of the space is reserved for overhead. This enables the operating system to reorganize the filesystem, store blocks temporarily, etc. This space is absolutely essential for the operation of the filesystem. Currently, the reserved block % is about 5% on an ext2 filesystem. You should not decrease this number unless you understand the issue better than I do.
Superblock
You can retrieve various bits of information from the superblock using the filesystem tuning tools, as described in a later section.
Tuning Parameters
Besides these basic filesystem parameters a handful of tunable
parameters are placed in the superblock. These govern such things as
when the filesystem is checked and the default mount options that are
applied to it. These will be discussed in the section on filesystem
tuning later.
| Prev | This page was made entirely with free software on linux: Kompozer and Openoffice.org |
Next |
